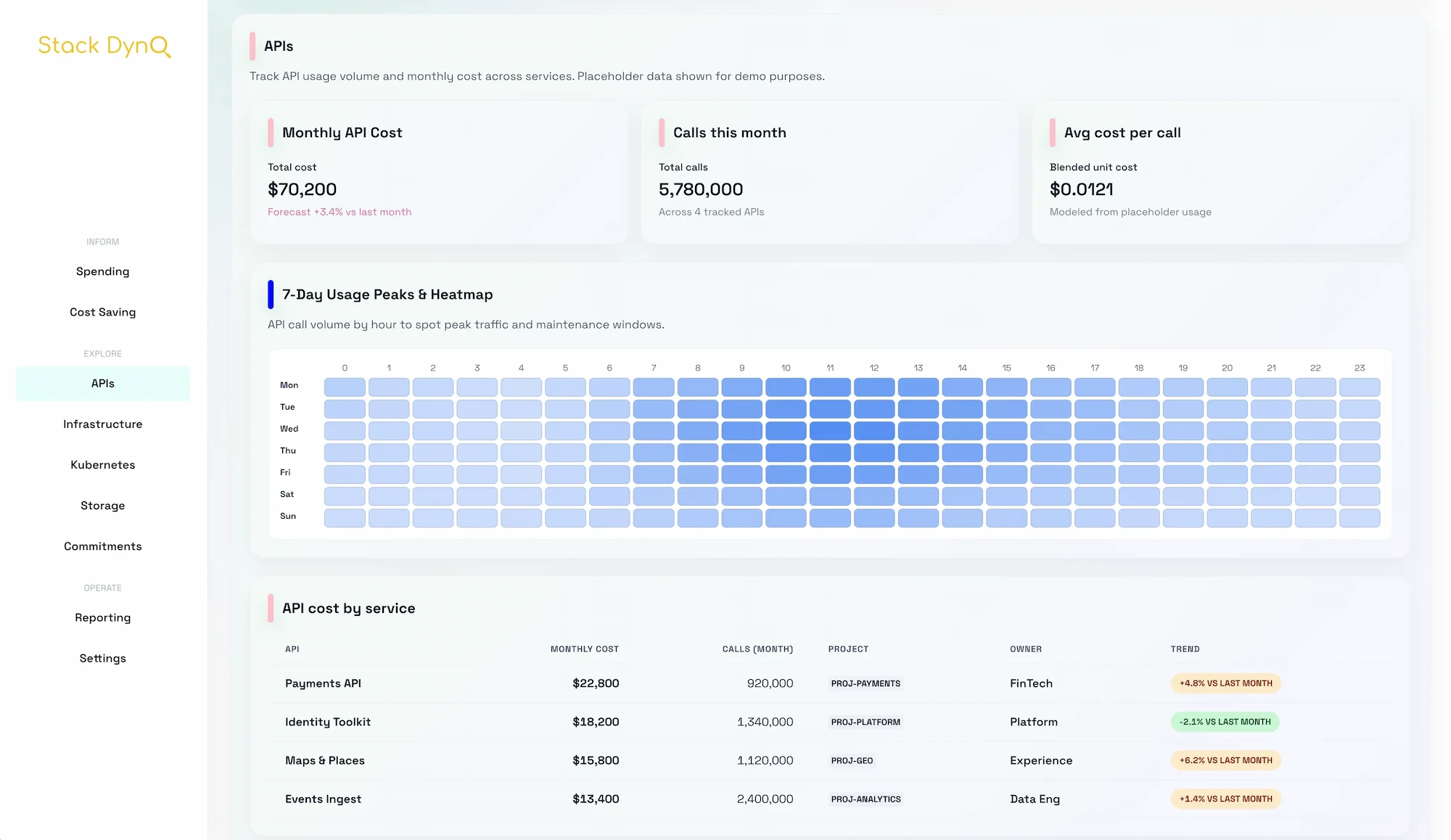
Dec 15, 2025FinOps for LLM inference: cost per 1k tokens without guesswork
Measure and tune prompt, model, and routing choices so customers get fast responses and you keep margin.
Inference spend scales with usage, but waste scales with poor defaults. A clear view of cost per 1,000 tokens keeps latency, quality, and margin balanced.
Before diving in, anchor the metrics: latency, quality, and cost must be visible together. Otherwise, teams optimize the wrong dimension.
- Track tokens in/out, model family, and prompt template version on every request.
- Label requests by product, customer tier, and environment for allocation.
- Capture retries and fallbacks; they often double the cost silently.
- Prompt shape: shorten system prompts, favor concise few-shot examples, and cache shared context.
- Model routing: send low-risk requests to smaller models; reserve frontier models for complex tasks.
- Batching & streaming: batch background jobs; stream user-facing responses to improve perceived speed.
import { trackInference } from './sdk';
await trackInference({
model: 'mixtral-8x7b',
tokensIn: 540,
tokensOut: 210,
latencyMs: 320,
promptTemplate: 'support-summary-v3',
tags: { customer: 'acme', env: 'prod', product: 'support' },
});
- API cost tracking shows cost-per-call by model and prompt variant.
- Anomaly alerts fire when retries spike or cost per 1k tokens drifts beyond thresholds.
- Spending flow ties LLM usage back to the products and customers that drove it.
Before diving in, give readers a quick narrative so the checklist lands with context. Share both quality and cost so teams see the trade-offs clearly.
- Weekly note: top routes by spend, wins shipped (prompt reductions, routing tweaks), and the single riskiest path.
- Monthly PDF to finance with unit-cost trends and forecast for the next quarter.
- A backlog of routing and prompt experiments with expected savings and owners.
LLM inference can stay fast and affordable when levers are explicit. Stack Dyno keeps the measurements, alerts, and reports in one place so optimizations stick.
Thanks for reading. Share feedback or ask for deeper dives on any topic.
View Stack Dyno