Moving to GKE Autopilot is not a lift-and-shift; it is a sizing exercise with business expectations attached. A structured play helps partners migrate safely while proving the savings in Stack Dyno.
Start with observability, not cluster changes. The more you know up front, the less time you spend rolling back.
- Capture current request/limit ratios and utilization for each namespace.
- Map owners and environments so cost deltas roll up correctly after the move.
- Tag stateful services and latency-sensitive workloads that may need exceptions.
- Set a savings target per namespace based on historical over-allocation.
Treat the rollout like a release train, with checkpoints between each wave.
- Start with staging clusters and low-risk namespaces to validate performance.
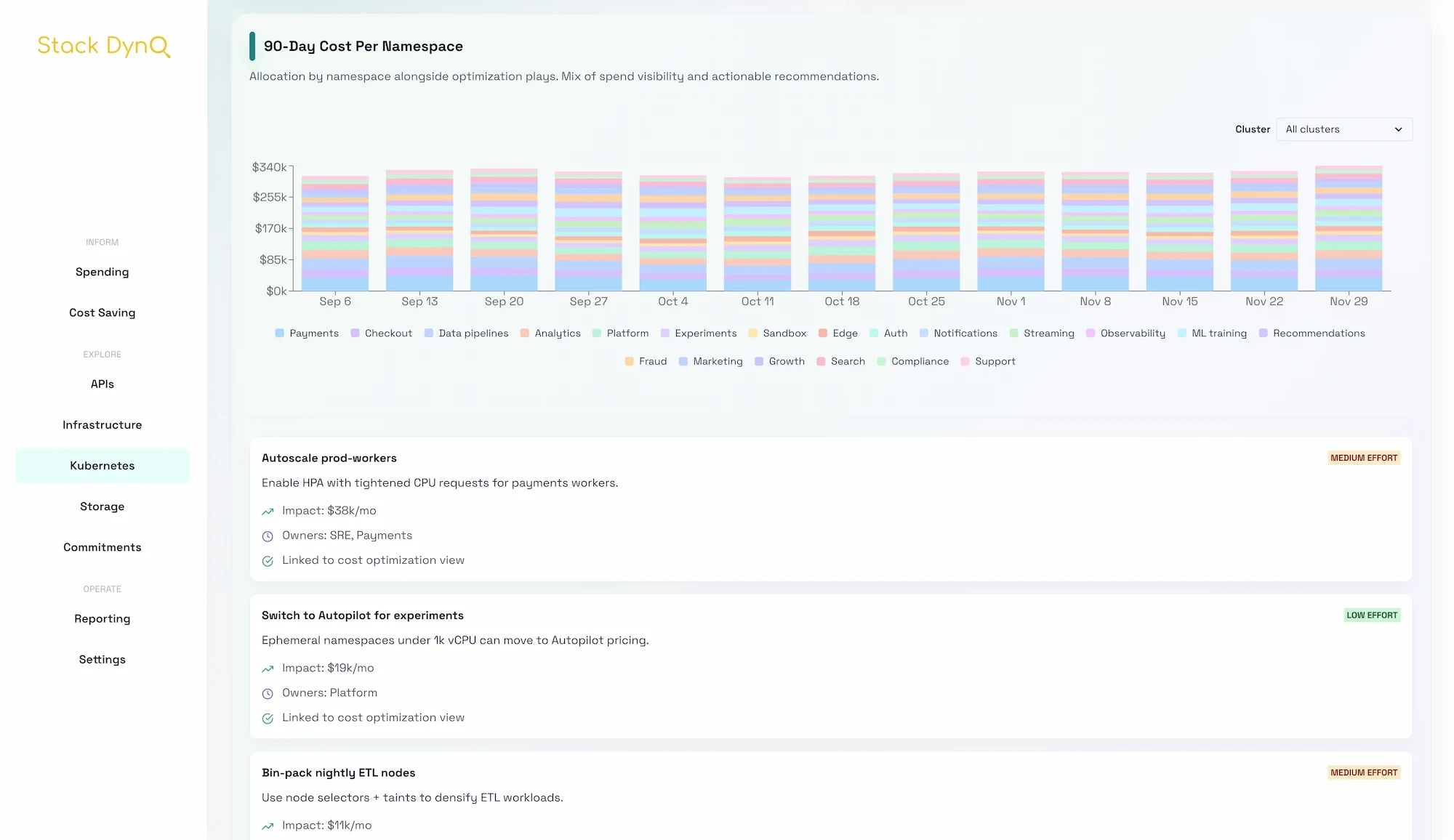
- Enable Stack Dyno’s Kubernetes allocation view to monitor cost per namespace pre/post move.
- Compare autoscaling events and pod eviction rates to confirm stability.
- Roll out production namespaces in waves with rollback windows defined.
Savings claims land better with a before/after story and a reliability note.
- Use Stack Dyno’s spending flow to show before/after spend by service and customer.
- Publish a weekly Autopilot variance report to Slack with the top five savings drivers.
- Track CPU and memory efficiency scores to prove optimization beyond pure cost.
Capture learnings while they are fresh; they become defaults for the next migration.
- Update default pod requests based on the most efficient namespaces.
- Add Autopilot as a recommended path in your internal service catalog.
- Keep a migration backlog visible in Stack Dyno so account teams can champion the next wave.
A disciplined Autopilot play helps customers trust the move and keeps your margin intact. Stack Dyno supplies the allocation visibility, alerts, and reporting needed to call the win clearly.
Thanks for reading. Share feedback or ask for deeper dives on any topic.
View Stack Dyno