Small adjustments to scheduling, partitioning, and retries that save big dollars.
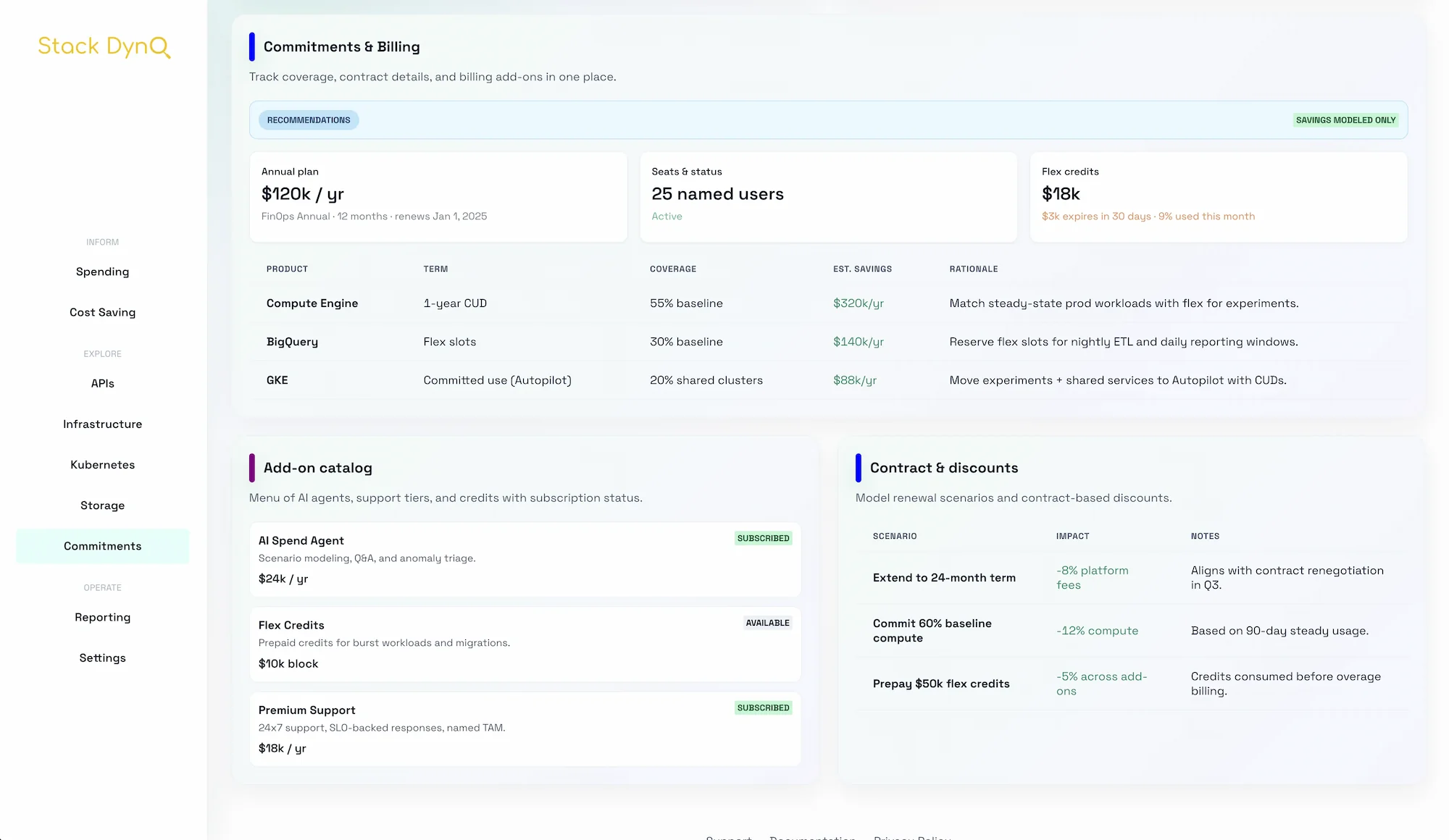
Data pipelines often run on autopilot until bills spike. A few tuning steps reduce cost and improve reliability.
Before diving in, tie the actions to a clear outcome instead of a generic task list.
Before diving in, give readers a quick narrative so the checklist lands with context.
Before diving in, tie the actions to a clear outcome instead of a generic task list.
Tuning pipelines is steady, high-ROI work. Stack Dyno keeps the metrics and reporting in one place so data teams can iterate confidently.
Thanks for reading. Share feedback or ask for deeper dives on any topic.
View Stack Dyno