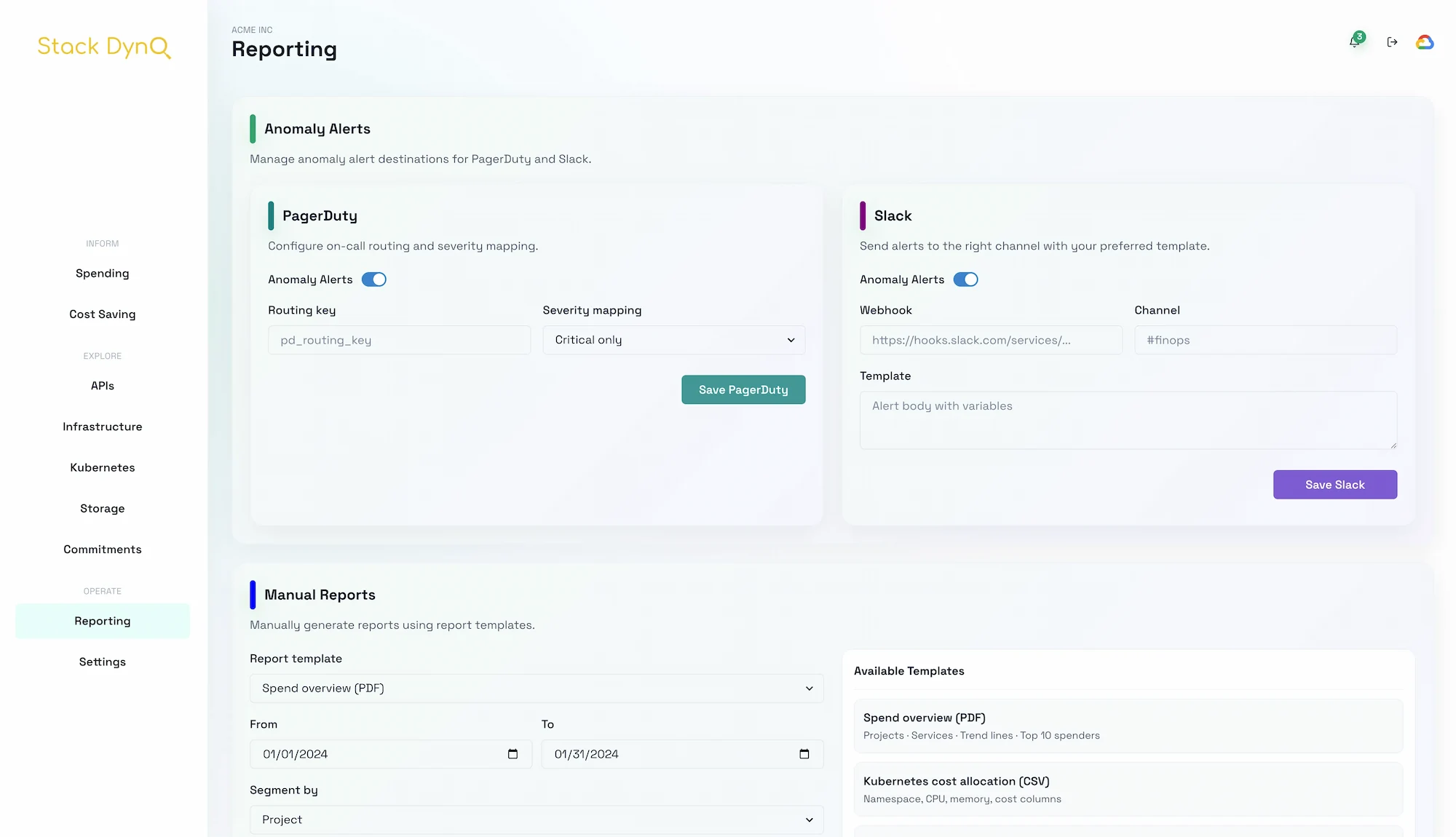
Spend spikes do not scare finance; unexplained spikes do. An anomaly runbook that pairs data with decisions keeps everyone calm when Google Cloud costs move unexpectedly.
Finance teams want clarity more than detail. Each alert should answer the “so what?” without forcing anyone to dig.
- Dollar impact, not just percent change, with the affected projects and SKUs.
- Owner and environment labels so finance knows who to call.
- One recommended action with a rollback plan.
- A link back to Stack Dyno with the filter pre-applied.
Triage should feel like checking a flight status, not a forensic investigation.
- Open the Stack Dyno anomaly alert and confirm it is outside the normal seasonality window.
- Check recent deployments or pipeline changes in the linked project timeline.
- Compare the spending flow before and after the spike to see which teams are impacted.
- Escalate only if the variance persists for more than one billing cycle or threatens margin.
Noise kills trust fast. Make it easy to retire bad rules and replace them with better ones.
- Tune thresholds by business unit; finance prefers fewer, higher-confidence alerts.
- Archive noisy services and route them to Slack instead of PagerDuty.
- Review false positives monthly and update the baseline in Stack Dyno so the model learns.
Close the loop so leaders do not have to ask if the issue was solved.
- Summarize the root cause, fix, and expected savings in a weekly Stack Dyno PDF.
- Track time-to-detect and time-to-acknowledge for each anomaly to show improvement.
- Keep a simple ledger of anomalies closed with dollar impact so finance sees value.
A crisp runbook turns anomalies into proof that your FinOps practice works. Stack Dyno keeps the alert, context, and follow-up in one place so finance always knows what happened next.
Thanks for reading. Share feedback or ask for deeper dives on any topic.
View Stack Dyno